








Your complimentary articles
You’ve read one of your two complimentary articles for this month. To have complete access to the thousands of philosophy articles on this site, please
You can register for a free account to have four complimentary articles per month. We will occasionally email you a newsletter, from which you can unsubscribe at any time. We do not sell personal data or otherwise disclose personal information to other organisations.
Future Shocks
Pascal’s Artificial Intelligence Wager
Derek Leben computes the risks of general AI.
In 2008 European physicists at CERN were on the verge of activating the Large Hadron Collider to great acclaim. The LHC held the promise of testing precise predictions of the most important current theories in physics, including finding the elusive Higgs Boson (which was indeed successfully confirmed in 2012). However, some opponents of CERN’s activation raised an almost laughable objection, encapsulated in a lawsuit against CERN from the German chemist Otto Rossler, that switching the LHC on might create a miniature black hole and destroy the Earth. In response, most physicists dismissed the chances of such a catastrophe as extremely unlikely, but none of them declared that it was utterly impossible. This raises an important practical and philosophical problem: how large does a probability of an activity destroying humanity need to be in order to outweigh any potential benefits of doing it? How do we even begin to weigh a plausible risk of destroying all humanity against other benefits?
Recently, prominent figures such as Sam Harris and Elon Musk have expressed similar concerns about the existential risks to humanity posed by the creation of artificial intelligence. This follows earlier work by Nick Bostrom (see for instance his ‘Ethical Issues in Advanced Artificial Intelligence’, 2004) and Eliezer Yudkowsky (for example, ‘Artificial Intelligence as a Positive and Negative Factor in Global Risk’, 2008). Let’s call this position ‘Anti-Natalism’ about artificial (general) intelligence, since it proposes that the overall risks of creating AI outweigh its expected benefits, and so demands that AI shouldn’t be brought to birth.
Unlike Otto Rossler’s worries about the LHC, which were largely dismissed by the scientific community, several research groups, including the Future of Life Institute, the Machine Intelligence Research Institute, and the Cambridge Centre for the Study of Existential Risk, have dedicated millions of dollars’ worth of thought to exploring the dangers of machine intelligence. Indeed, the new field of ‘existential risk’ includes AI among its chief concerns – alongside climate change, nuclear proliferation, and large-scale asteroid impacts. The same conundrum still applies as with Rossler’s concern: how high does the probability of AI destroying humanity need to be in order to outweigh its potential benefits?
The Mathematician’s Divine Bet
One answer to this question comes from an unexpected source: Blaise Pascal’s argument for believing in God.
In his Pensées (1670), Pascal proposed that you can expect much better outcomes if you put your faith in God compared to not believing. Specifically, if there is any chance that God rewards those who believe in him with eternal happiness and punishes those who do not believe with eternal suffering, then it makes sense to believe in Him, since if He exists the payoffs will be infinite (and potential losses similarily), and will always vastly outweigh the finite payoffs that one could receive if one does not believe. So believing in God is a good bet, indeed the only rational bet, even if it is more likely than not that God does not exist. Even assigning an extremely low probability to God’s existence, any chance of receiving infinite gains or losses should be immediately motivating.
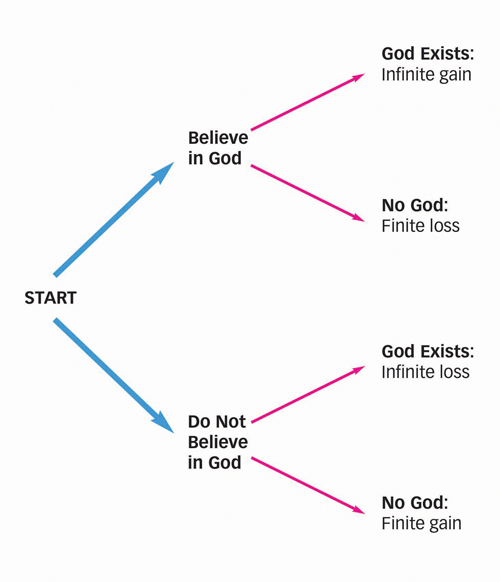
Decision tree for Pascal's Wager
Pascal’s Wager has generated a vast academic literature (the collection edited by Bartha and Pasternack, Pascal’s Wager, 2018, provides a helpful overview). There’s even a case to be made that it was the first application of modern decision theory. Yet there are a host of strong objections to the argument, which have led it to be largely disregarded in mainstream philosophy. The most prominent objections to Pascal’s Wager are as follows:
• Psychological impossibility: It is impossible to force oneself to believe some proposition, even if that belief will likely produce high benefits.
• Moral impermissibility: There is something morally objectionable about believing in God based on expected benefit – as opposed, for instance, to believing because you think there are good reasons for believing.
• Infinite utilities: There is a problem with assigning infinite utility to any outcome. What does infinite gain even mean?
• Many gods: There are many possible gods, who might punish belief in the wrong god with infinite costs. In other words, how do you know which religion to bet on?
I think each of these objections is extremely effective, although there do exist well-thought-out responses from contemporary defenders; for instance, Lycan and Schesinger, ‘You Bet Your Life’ (1988); Jordan, Pascal’s Wager (2006); Rota, ‘A Better Version of Pascal’s Wager’ (2016). But this debate will not be relevant for our discussion. Instead, the structure of Pascal’s Wager will provide us with a useful framework for debating Anti-Natalism about AI – the position that artificial intelligence is too dangerous to create…

Shift In Control by Cameron Gray 2020
Please visit parablevisions.com and facebook.com/camerongraytheartist
Plausibility & Catastrophe
The main insight from Pascal relevant to the debate about AI is this: any probability of infinite losses will always outweigh any possible finite gains.
To modify the idea slightly, we can add the qualification that the probability of an event must cross some plausibility threshold to be considered. Rossler’s worry about the LHC creating a black hole that swallows the Earth may not qualify as a plausible existential risk, while AI could. And according to Pascalian reasoning, once an event crosses into being a plausible risk of entailing infinite losses, we must assign it infinitely negative expected value, and act against it.
Using this as standard, the Anti-Natalist argument against AI looks like this:
1. If an event has a plausible likelihood of infinite losses then its risk outweighs any finite expected benefits.
2. AI destroying humanity would be an infinite loss.
3. There’s a plausible likelihood that AI will destroy humanity.
Conclusion: Therefore, the potential risks of AI outweigh any potential benefits.
I find each of these premises, and so the argument itself, extremely credible.
First, Anti-Natalists have presented a very good case that there is a significantly high probability to AI disaster. As Bostrom describes in Superintelligence: Paths, Dangers, Strategies (2014), there are a wide variety of possible values, so it’s extremely likely that the values of a superpowerful AI will eventually come into conflict with the values of humans; and the easiest way to resolve such a conflict would be to exterminate humanity. If an AI destroys humanity, that would constitute the destruction of everything we currently know and care about. This would be a catastrophe of perhaps infinite loss. Let’s call this event AI Catastrophe α.
However, even if we accept everything that the Anti-Natalist has said and the Pascal-style decision-tree set up to describe it, there may still exist some potential infinite payoffs that are being ignored. Or to put this the other way round, there may be some infinite losses associated with not creating AI!
In his great short story ‘The Last Question’ (1956), Isaac Asimov depicts a future where humanity has colonized the observable universe. The only remaining question about the survival of intergalactic human civilization is whether it can defeat the apparently inevitable heat death of the universe produced as a result of the second law of thermodynamics.
In the story, the success of humanity has largely been driven through AI – representing a rare instance of optimism in sci fi amongst the mostly bleak depictions of both future human civilization and AI. But in this, the story raises an important question: does the future continuation and spread of human civilization depend on the creation of superintelligent AI?
It’s important to realize that this question is contingent and empirical: that there exists some yet-unknown probability to the prediction ‘Humanity can’t survive the various threats to its continued existence without creating superintelligent AI’. If it turns out that this prediction is true and we have not developed AI, this would mean the destruction of human life and everything that it has ever worked towards, so the result would be the same as our original AI Catastrophe α. Therefore, in the spirit of labelling, let’s call the idea that humanity goes extinct as a result of not creating general AI, AI Catastrophe β. Whatever likelihood you assign to Catastrophe β, as long as the probability of it is sufficiently larger than zero to be plausible, this potential catastrophe must also be an essential part of calculating the wisdom or otherwise of creating AI.
I find Catastrophe β to be well above the plausibility threshold, but this is only a personal credence. Inserting Catastrophe β into the decision-tree for creating AI will completely alter the calculations:
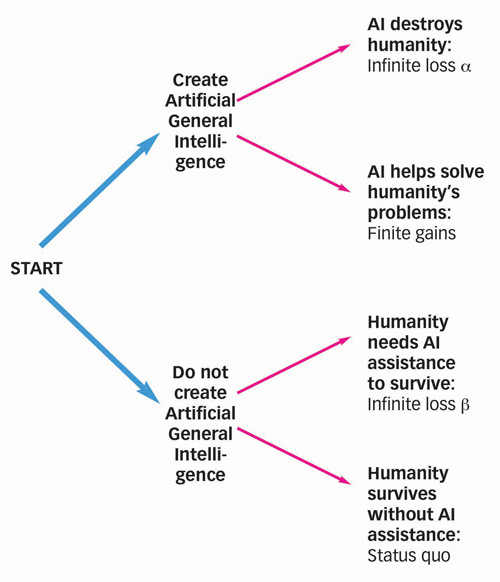
Decision tree for developing AI
In this new decision-tree, Pascal-style reasoning concludes that if both Catastrophe α and Catastrophe β cross the plausibility threshold, their infinite negative utilities cancel each other out! So the existential risk posed by creating AI is cancelled out by the existential risk of not creating AI! The only considerations remaining are the potential benefits of AI compared with the status quo payoffs of not having AI. In that contest, creating AI will clearly win out. This is easy to see when we remember that the possible ‘finite gains’ included in this category include things like an end to poverty, disease, boredom, and warfare. Therefore, Pascalian reasoning will lead to the conclusion that creating AI is always a better choice for humans.
The Nuclear Wager
This argument may be more intuitive when applied to more familiar existential risks. For example, people who historically opposed the development of nuclear weapons often assumed that the payoff for not developing them is simply a straightforward gain or loss to the status quo. However, there is an argument associated with political scientist Kenneth Waltz (‘The Spread of Nuclear Weapons: More May Be Better’, 1981) that nuclear weapons have provided a deterrent effect that produced the long peace that has existed between large nation-states since 1945. An even stronger version of Waltz’s position would propose that only nuclear weapons could have this peaceable effect. Waltz’s claim is extremely contentious, the stronger version of it even more so, and I will not defend either. However, it must be entertained by those who object to the proliferation of nuclear weapons. If some plausible likelihood is attached both to a nuclear holocaust caused by nuclear weapons, and to a non-nuclear holocaust, produced in the absence of nuclear weapons, then similar reasoning to the AI case could apply here too.
Do the gains of having nuclear weapons outweigh the gains of not having them? That isn’t easy to assess. But the finite gains of AI are much easier to evaluate. Given the plausibility of ultimate catastrophe either with or without AI, it could be that we only need consider the possible benefits.
© Dr Derek Leben 2020
Derek Leben is Department Chair and Associate Professor of Philosophy in the University of Pittsburgh at Johnstown.
Advertisement
